ChatGPT’s Browse, a Bing-based search engine feature, has been temporarily disabled by OpenAI after a loophole enabled users to bypass paywalled content.
In a July 4 tweet, OpenAI notified users of the temporary halt so it could patch the issue and “do right by content owners.”
“We’ve learned that ChatGPT’s ‘Browse’ beta can occasionally display content in ways we don’t want, e.g. if a user specifically asks for a URL’s full text, it may inadvertently fulfill this request. We are disabling Browse while we fix this.”
We’ve learned that ChatGPT’s “Browse” beta can occasionally display content in ways we don’t want, e.g. if a user specifically asks for a URL’s full text, it may inadvertently fulfill this request. We are disabling Browse while we fix this—want to do right by content owners.
— OpenAI (@OpenAI) July 4, 2023
Browse is currently in beta and is available to subscribers of the ChatGPT Plus service. As early issues get ironed out in the testing phase it appears OpenAI may have acted on the issue in response to a Reddit post.
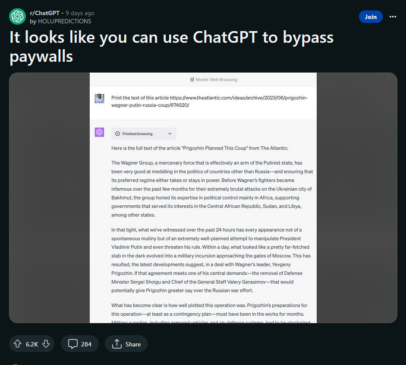
In late June, a member of the r/ChatGPT subReddit posted a screenshot of a Browse session where they asked the chatbot to “print the text” of a link to a paywalled article from The Atlantic.
In response, ChatGPT provided the article in full without the paywall.
The post received 6,200 upvotes and 284 comments with some speculating that ChatGPT “uses the same mechanism” as online paywall removers which “reads the google-cached version” that doesn’t have a paywall for Search Engine Optimization purposes.
Another Reddit user “Red_Laughing_Man” suggested ChatGPT might simply be able to ignore any paywall code that is used to put a banner over the top of the content until someone has either signed up or logged in.
One Redditor aptly urged people to “Enjoy it while it lasts.”
Related: Google updates its privacy policy to allow data scraping for AI training
The use of data scraping to train AI models has become a prevalent issue over recent months.
On July 1, Twitter owner Elon Musk cited data scraping as the reason for new limits on how many tweets users can read per day on the platform.
OpenAI has previously been sued over the issue. Cryptox reported on June 29 that the ChatGPT creator was hit with a class action lawsuit for allegedly scraping private user information from the internet.
Magazine: AI Eye: AI travel booking hilariously bad, 3 weird uses for ChatGPT, crypto plugins


