

This post is part of our ongoing Call for Input on developing the ICO framework for auditing AI. We encourage you to share your views by leaving a comment below or by emailing us at AIAuditingFramework@ico.org.uk.
In addition to exacerbating known data security risks, as we have discussed in a previous blog, AI can also introduce new and unfamiliar ones.
For example, it is normally assumed that the personal data of the individuals whose data was used to train an AI system cannot be inferred by simply observing the predictions the system returns in response to new inputs. However, new types of privacy attacks on Machine Learning (ML) models suggest that this is sometimes possible.
In this update we will focus on two kinds of these privacy attacks – ‘model inversion’ and ‘membership inference’.
While the ICO’s overall Security guidelines already apply, as part of our AI auditing framework we are keen to hear your feedback about what you think would be reasonable approaches to threat modelling in relation to these attacks, and other best-in-class organisational and technical controls to address them.
Model inversion
In a model inversion attack, if attackers already have access to some personal data belonging to specific individuals included the training data, they can infer further personal information about those same individuals by observing the inputs and outputs of the ML model. The information attackers can learn goes beyond generic inferences about individuals with similar characteristics.
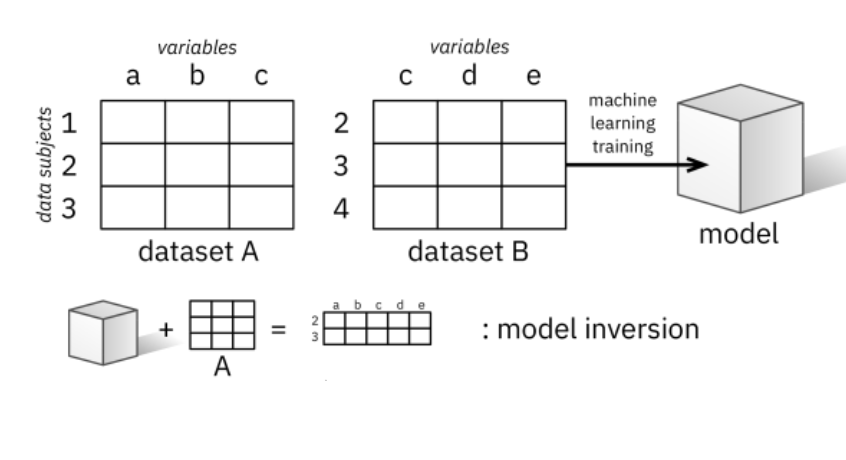
Figure 1. Illustration of model inversion and membership inference attacks, reproduced from Veale et al. ‘Algorithms that remember: model inversion attacks and data protection law’
An early demonstration of this kind of attack concerned a medical model designed to predict the correct dosage of an anticoagulant, using patient data including genetic biomarkers. It proved that an attacker with access to some demographic information about the individuals included in the training data could infer their genetic biomarkers from the model, despite not having access to the underlying training data.
Another recent example demonstrates that attackers could reconstruct images of faces that a Facial Recognition Technology (FRT) system has been trained to recognise. FRT systems are often designed to allow third parties to query the model. When the model is given the image of a person whose face it recognises, the model returns its best guess as to the name of the person, and the associated confidence rate.
Attackers could probe the model by submitting many different, randomly generated face images. By observing the names and the confidence scores returned by the model, they could reconstruct the face images associated with the individuals included in the training data. While the reconstructed face images were imperfect, researchers found that they could be matched (by human reviewers) to the individuals in the training data with 95% accuracy (see Figure 2)

Figure 2. A face image recovered using model inversion attack (left) and corresponding training set image (right), from Fredriksen et al., ‘Model Inversion Attacks that Exploit Confidence Information’
Membership inference
Membership inference attacks allow malicious actors to deduce whether a given individual was present in the training data of a ML model. However, unlike in model inversion, they don’t necessarily learn any additional personal data about the individual.
For instance, if hospital records are used to train a model which predicts when a patient will be discharged, attackers could use that model in combination with other data about a particular individual (that they already have) to work out if they were part of the training data. This would not reveal any individual’s data from the training data set per se, but in practice it would reveal that they had visited one of the hospitals that generated the training data during the period the data was collected.
Similar to the FRT example above, membership inference attacks can exploit confidence scores provided alongside a model’s prediction. If an individual was in the training data, then the model will be disproportionately confident in a prediction about that person, because it has seen them before. This allows the attacker to infer that the person was in the training data.
The gravity of the consequences of models’ vulnerability to membership inference will depend on how sensitive or revealing membership might be. If a model is trained on a large number of people drawn from the general population, then membership inference attacks pose less risk. But if the model is trained on a vulnerable or sensitive population (eg patients with dementia, or HIV), then merely revealing that someone is part of that population may be a serious privacy risk.
Black vs white box attacks
There is an important distinction between ‘black box’ and ‘white box’ attacks on models. These two approaches correspond to different operational models.
In white box attacks, the attacker has complete access to the model itself, and can inspect its underlying code and properties (although not the training data). For example, some AI providers give third parties an entire pre-trained model and allow them to run it locally. White box attacks enable additional information to be gathered – such as the type of model and parameters used – which could help an attacker in inferring personal data from the model.
In black box attacks, the attacker only has the ability to query the model, and observe the relationships between inputs and outputs. For example, many AI providers enable third parties to access the functionality of an ML model online to send queries containing input data and receive the model’s response. The examples we have highlighted in above are both black box attacks.
White and black box attacks can be performed by providers’ customers or anyone else with either authorised or unauthorised access to either the model itself, or its query or response functionality respectively.
Other new AI security challenges
Models with training data included by design
Model inversion and membership inferences show that AI models can inadvertently contain personal data. It is worth flagging that there are also certain kinds of ML models which actually contain parts of the training data in its raw form within them by design (i.e. no ‘attacks’ are necessary). For instance, ‘support vector machines’ (SVMs) and ‘k-nearest neighbours’ (KNN) models contain some of the training data in the model itself. In such cases, access to the model by itself will mean that the organisation purchasing the model will already have access to some of the personal data contained in the training data, without having to exert any further efforts. Providers of such ML models, and organisations procuring them, should be aware that they contain personal data. Storing and using such models would therefore constitute processing of personal data and as such, the standard data protection provisions would apply.
Adversarial examples
While this update is about the risks of AI models revealing personal data, there are other potential novel AI security risks, such as ‘adversarial examples’.
These are examples fed to an ML model, which have been deliberately modified so that they are reliably misclassified. These can be images which have been manipulated, or even real-world modifications such as stickers placed on the surface of the item. Examples include pictures of turtles which are classified as guns, or road signs with stickers on them, which a human would instantly recognise as a ‘STOP’ but an image recognition model does not.
While such adversarial examples are concerning from a security perspective, they might not in and of themselves raise data protection concerns if they don’t involve personal data. However, there may be cases in which adversarial examples are indeed a data protection risk. For instance, some attacks have been demonstrated on facial recognition systems. By slightly distorting the face image of one individual, an adversary can trick the facial recognition system into misclassifying them as another (even though a human would still recognise the distorted image as the correct individual). This would raise concerns about the system’s accuracy, especially if the system were to be used to make legal or similarly significant decisions about data subjects.
What should organisations do?
Organisations which train models and provide them to others should assess whether those models may contain personal data, or are at risk of revealing it if attacked. They should assess whether the individuals contained in the training data may be identified or identifiable by those who may have access to the model. They should assess the means that may be reasonably likely to be used, in light of the vulnerabilities described above. As this is a rapidly developing area, organisations should stay up to date with the state of the art in both methods of attack and mitigation.
Security and ML researchers are still working to understand what factors make ML models more or less vulnerable to these kinds of attacks, and how to design effective protections and mitigation strategies.
One possible cause of ML models being vulnerable to privacy attacks is ‘overfitting’. This is where the model pays too much attention to the details of the training data, effectively almost remembering particular examples from the training data rather than just the general patterns. Model inversion and membership inference attacks can exploit this. Avoiding overfitting will help, both in mitigating the risk of privacy attacks and also in ensuring that the model is able to make good inferences on new examples it hasn’t seen before. However, avoiding overfitting will not completely eliminate the risks. Even models which are not overfitted to the training data can still be vulnerable to privacy attacks.
In cases where confidence information provided by a ML system can be exploited, as in the FRT example above, the risk could be mitigated by not providing it to the end user. This would need to be balanced against the need for genuine end users to know whether or not to rely on its output, and will depend on the particular use case and context.
Equally, if the model is going to be provided via an Application Programming Interface (API), the provider could monitor queries from its users, in order to detect whether the API is being used suspiciously. This may indicate a privacy attack and would require prompt investigation, and potential suspension or blocking of a particular user account. Such measures may become part of common real-time monitoring techniques used to protect against other security threats, such as ‘rate-limiting’ (reducing the number of queries that can be performed by a particular user in a given time limit).
If a model itself is going to be provided in whole to a third party, rather than being merely accessible to them via an API, then the model provider will be less easily able to monitor the model during deployment and thereby assess and mitigate the risk of privacy attacks on it. However, they remain responsible for ensuring that the personal data they used to train their models is not exposed as a result of the way clients have deployed the model. They may not be able to fully assess this risk without collaborating with their clients to understand the particular deployment contexts and associated threat models. As part of the procurement policy there should be sufficient information sharing between each party to perform their respective assessments as necessary. In some cases, ML model providers and clients will be joint controllers and therefore need to perform a joint risk assessment.
In cases where the model actually contains examples from the training data by default (as in SVMs and KNNs, mentioned above), this is a transfer of personal data, and should be treated as such.
Your feedback
We would like to hear your views on this topic and genuinely welcome any feedback on our current thinking. In particular, we would like to hear your opinions as to how to assess these risks, and how a proportional approach could be developed to control them.
Please share your views by leaving a comment below or by emailing us at AIAuditingFramework@ico.org.uk.
 |
 Dr Reuben Binns, a researcher working on AI and data protection, joined the ICO on a fixed term fellowship in December 2018. During his two-year term, Reuben will research and investigate a framework for auditing algorithms and conduct further in-depth research activities in AI and machine learning. |
|
 Andrew Paterson, Principal Technology Adviser, contributes technical expertise within the ICO, particularly regarding information security. His current focus is on developing the ICO’s cybersecurity guidance aimed at helping organisations comply with GDPR and the 2018 Data Protection Act. |
||



{kind=link}